Optical Character Recognition (OCR) is the process that converts an image of text into a machine-readable text format. For example, if you scan a form or a receipt, or you receive a scanned PDF or image from a client, the OCR facility will evaluate that object, extract the text, and save the resulting information to a database. Certainly, in the finance industry (where we assign virtually all of our efforts), the tool is invaluable since it returns information in a way that can be further evaluated, searched, or acted upon by way of triggers.
An OCR facility is integrated with Yabber, although the tool is also available via a standalone AI-driven API accessed with your client API key. This article provides information on how the tool might be used to improve upon your digital workflows.
History: We've always provided an OCR API, but we hadn't really used it much ourselves until it came time to archive the Royal Commission data. The exhibits and submissions were largely scanned documents, so we were required to use OCR in order to build our BRC API and searchable archive. In company with the transcripts of each session, we've since created the only authoritative reference to the BRC available online. We've since integrated the OCR API with a large number of applications. For the last couple of years, and for general statistical purposes, we've automated the OCR to evaluate the images used as part of mortgage broker advertising in order to identify non-compliance.
The reliability of the resolved text is excellent. An AI backend learns more about text the more it is exposed to new fonts or handwriting.
Purpose of the API
For clients, the purpose of the API functionality will become more evident as we release Yabber modules that aren't 'generally' available. At the top of this list is the website-based fileUploader functionality. The Nuntius module evaluates incoming emails for attachments before archive them into a 'client file' (unreleased simply because we don't have resource at the moment to assign to additional support). A great deal of information can be resolved from those files uploaded or sent by clients, and the contents of these files is often useful as a 'searchable' CRM note.
Supporting our AI ambitions, various sources of text have to be ingested into the system in a way that can be indexed and searched, and the OCR tools allow us to include scanned documents from various sources.
During the last few years, we've used the tool (as part of testing) to archive the scanned documents made available via the Royal Commission, and we've also created searchable text archives of the 'JFK files' and various documentation released by the CIA, all of which we'll release in standalone resources when time permits.
OCR in Yabber
If assigned to your account, the OCR module is found in the 'Resources' section. You may upload via a drag and drop panel, and the result will either be queued or returned immediately. When uploading, an optional webhook may be selected for those cases where another application processes the results. A table shows all your OCR files and their results.
Trigger functionality is forthcoming. We expect to integrate triggers associated within the content of supplied documents and/or images, but we're yet to determine the most intuitive method for clients to supply their own rules. You may review the Yabber development timelines for any updates.
Using the API
Introduction
While the OCR facilities are available in Yabber, you may integrate the system with your own application using a RESTful API. Because large files can potentially be submitted, there may be a delay in returning the resolved text. For smaller files, you should expect the text in the initial response - otherwise you'll have to create a webhook, or optionally poll the API to check on the status.
The system accepts PDF documents and images. All other file types are rejected.
Submitting Files
The API expects an array of images or PDF documents. The following function is an example of how you might submit your resources.
We evaluate every page of any PDF submitted so there will be a delay in a response. The files aren't evaluated immediately; instead, they're queued and will be processed in turn. Smaller files are processed immediately with an appropriate response returned. The is_processed value will indicate whether the resource was queued or processed.
Updating Project: To update a project, include the project ID in the request. This action simply makes it easier to managed archived material, and makes it easier to search from within the OCR text assigned to a specific project resource.
Name: Assignment of a name in the request is used only to make the information more human-friendly in Yabber. If a custom name isn't assigned we'll simply use the date.
A response will be returned as follows:
Note that if a scheduled field is showing anything other than 0, the job was queued. Each document is returned under a parent project ID. Each individual page for each submitted resource is shown in an array with a link to the applicable image (each PDF is segmented into images, with each page rendered as a single image).
Text: Note the 'text' field associated with each document (in our case, empty). If the OCR project is evaluated immediately, this field will be populated with the applicable text.
Version 1: We've operated an OCR API since 2018, with the current version sitting at 1.6.2. In all cases, complete backwards compatibility applies for earlier versions, and the functions and features remains the same. A version number need not be applied to the request unless you're a Beta tester for version 2.
When processing is complete, a webhook to a nominated URL is sent, or you can periodically poll to check the status update (the former is far more efficient and doesn't limit resources when API counts are throttled).
Get Projects and Documents
You should save the response data as you'll need the project and/or document ID in order to query the API. A sample function using PHP's file_get_contents() function is shown below.
If querying the entire project, exclude the document ID from the function (and the opposite applies). To return an aggregated word count for the evaluated resource, the $words argument should be set to true.
Depending on the number of documents submitted as part of a single project, the response can be quite large, and it can often be hundreds or even thousands of lines in length. It's for this reason that we created individual pages, so you can query each page in turn if required. The sample response below shows the OCR_TEXT_IN_HERE text in place of the actual resolved text (we used various RG documents for testing so the response was very large). Note that the is_processed field for each document will show a is_processed value of either 1 or 0.
If a webhook is registered in your initial request, the data sent is identical to the above with the exception that only the data array is sent. The creation of webhooks, and sample code to accept an incoming package, is detailed in an article titled "Webhooks in Yabber".
Conclusion
There will come a time where applications such as these will be redundant. AI is progressing at a speed that'll allow you to generate accurate results quickly with GPT-style tools. However, every AI system needs an OCR module, and our OCR facility is designed to support those AI-based tools we introduce in the future. However, our system provides a procedural efficiency in that's it is integrated with other systems.
The Text-to-Speech module is currently integrated with the facility, although given the nature of the documents you will normally use with the tool, and the often unpredictable nature of the output, it generally shouldn't be used.
With the recent update of the system it is possible that you will experience some bugs. If you encounter any issues, or have any feature requests, please make them known to us.
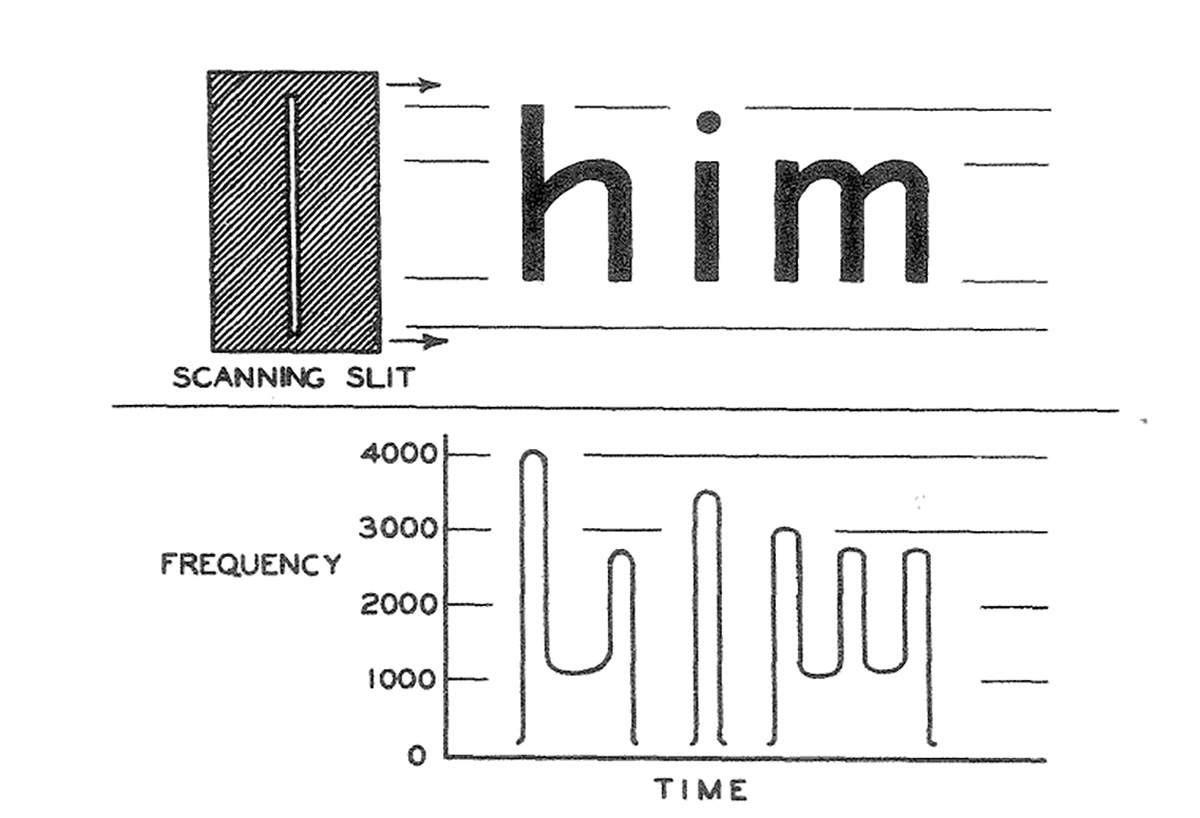
 to identify letters (linked image shows the tone generating method of the FM-SLIT reading machine, and below is the Frequency-time plot of its output - a common method applied to the earliest machines of its type). It is one of the earliest known applications of sonification. Dr. Edmund Fournier d'Albe of Birmingham University invented the optophone in 1913, which used selenium photosensors to detect black print and convert it into an audible output which could be interpreted by a blind person. The Glasgow company, Barr and Stroud, participated in improving the resolution and usability of the instrument. Only a few units were built and reading was initially exceedingly slow; a demonstration at the 1918 Exhibition involved Mary Jameson reading at one word per minute. Later models of the Optophone allowed speeds of up to 60 words per minute, though only some subjects are able to achieve this rate. Source: Wikipedia. [ View Image ]
to identify letters (linked image shows the tone generating method of the FM-SLIT reading machine, and below is the Frequency-time plot of its output - a common method applied to the earliest machines of its type). It is one of the earliest known applications of sonification. Dr. Edmund Fournier d'Albe of Birmingham University invented the optophone in 1913, which used selenium photosensors to detect black print and convert it into an audible output which could be interpreted by a blind person. The Glasgow company, Barr and Stroud, participated in improving the resolution and usability of the instrument. Only a few units were built and reading was initially exceedingly slow; a demonstration at the 1918 Exhibition involved Mary Jameson reading at one word per minute. Later models of the Optophone allowed speeds of up to 60 words per minute, though only some subjects are able to achieve this rate. Source: Wikipedia. [ View Image ]







{kind=link}
{kind=link}